最近看完了清华邓俊辉老师的数据结构与算法的课程,其中有些部分觉得听的时候十分费脑,所以想写下来作为一些总结。
首先希尔排序相较于其他排序方式,他是搭建于普通基础排序算法之上的一种排序方式,或者应该说是排序思路,如Adaboost一样,是从更高层的思路去解决问题。他是思路是:
- 引入一个序列H,如H={1,2,4,8,…,2^k}
-
将待排序数组,每次以序列中的数值k为宽度,取出每一段作为矩阵的行
-
按列排序
-
合并为线性组合,然后重复步骤2
-
此时的k是逆序的从序列中取如,取8、取4、取2,最后取1。
如下图:

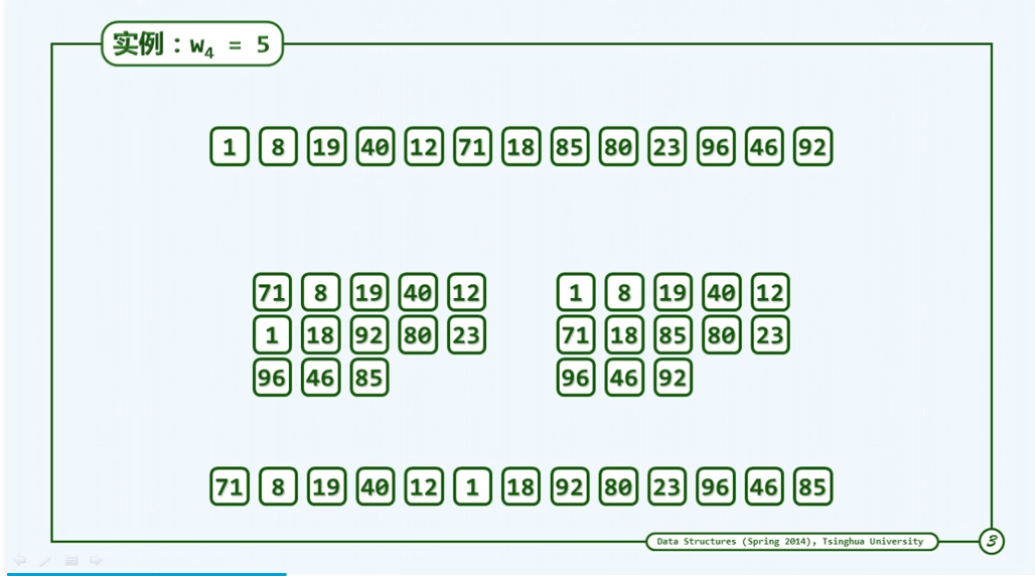
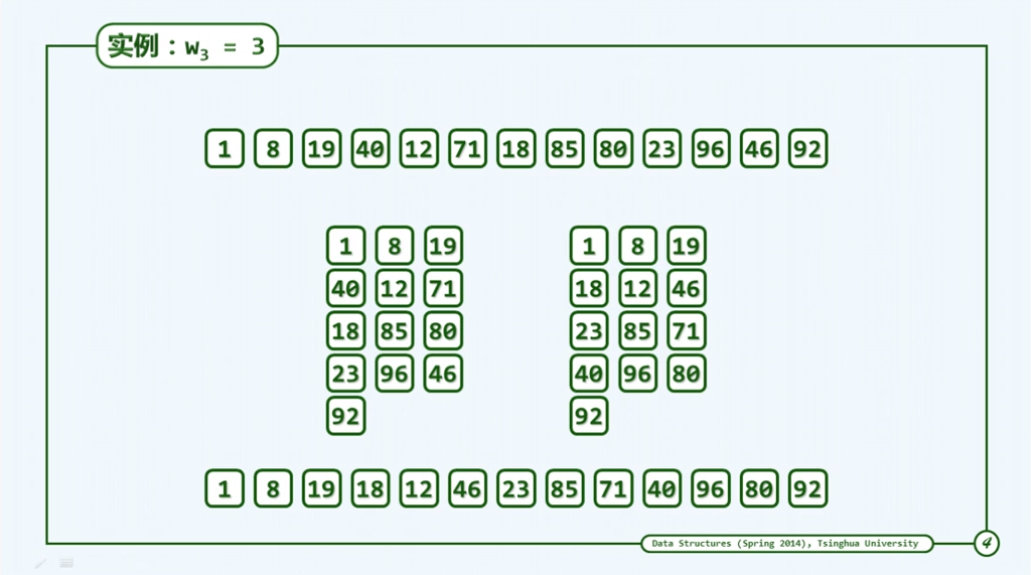
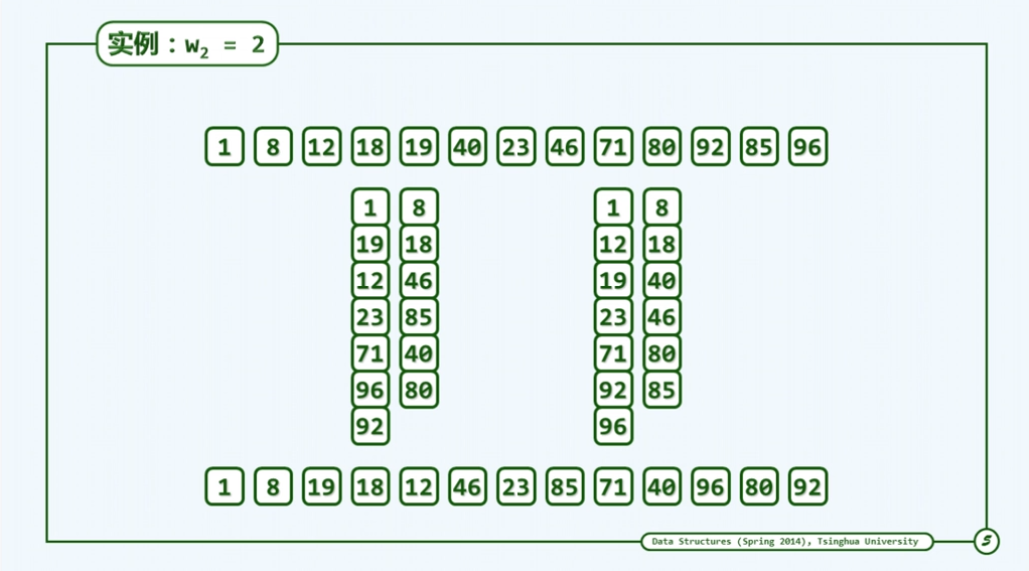

这个算法由于其处理步骤较多,因此表面看起来并不是非常的优秀,希尔算法其底层一般采用插入排序算法,而插入排序众所周知是一种输入敏感算法,其复杂度取决于逆序对的个数。接下来老师引出一个邮资问题,即假设4分和13分的邮票如何凑出50和35的邮资,构造函数f=4m+13n,可知当n,m∈{0,1,2,3…}时,是无法凑出50的邮资。此时我们可以把范围化的范一些,提出f=mg+nh(g,h分别为邮资),由数论可求出其最小无法凑出的数,如下图

即说明只要邮票面值够多且分布够合理就能凑出大多数面值
再回到希尔排序中,我们的目标是尽量的快速将待排序数组中的逆序对个数减少,希尔排序的思路是使某次k列排序中,每列达到有序状态,假如定为k-ordered,而由于k是递减的,我们假定h<k,则在完成h-sorting后,原数组同时满足(k,h)-ordered,即增加了数组的有序性,也可以理解邮资问题中的,更加的覆盖到更多邮资类型。
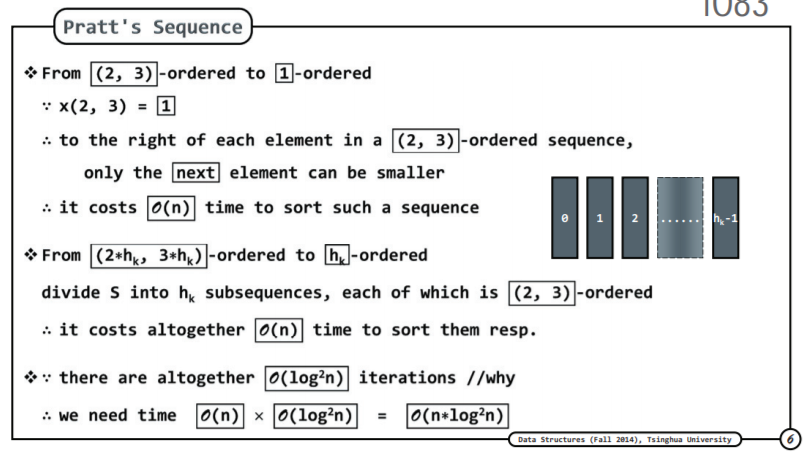
而很明显的是若采用序列{1,2,3,4,5,…,n}确实能够实现增强数组的有序性,但其列排序迭代次数也达到了o(n),明显达不到优秀排序算法o(nlogn)的要求。我们知道希尔排序的两大因素就是序列以及算法,在算法已经固定是插入排序的前提下,如何找到最优的序列就是实现最优的希尔排序的所要解决的问题了。因此采而典型的序列有希尔序列,PS序列,Pratt序列,Sedgewick序列,如下图






总结:
采用更优的序列,才能更好的提高希尔排序的性能,换句话说希尔排序的性能不仅仅是输入敏感的(受插入排序影响),也是条件(序列)敏感的。